
AIを使った画像生成って、最近めちゃくちゃ進化してきましたよね。
その中でも「Illustrious」っていうモデルが注目されています。これ、アニメっぽい画像を超高精度で生成できるんです。
この記事では、Illustriousがどんなモデルなのか、どんな可能性があるのかをざっくりとお話しします。気楽に読んでみてくださいね。
第1章: Illustriousモデルの概要
1.1 Illustriousって何?
IllustriousはStable Diffusion XL(SDXL)をベースにして作られた最新の画像生成モデルなんです。
Civitaiのリンク
最大で20MP(めちゃ高解像度!)の画像が作れるだけじゃなくて、色合いやディテールまでしっかり表現してくれるスゴいやつ。
たとえば「キャラクターの髪の毛をもっとふわっとさせたい」とか、
「背景を鮮やかに」みたいな細かい指示もバッチリ対応。アニメ好きにはたまりません。
1.2 どこがすごいの?
このモデル、いろんな面で進化してます。
まず、学習効率が抜群。バッチサイズとかドロップアウト制御を最適化したおかげで、サクサク学習して高品質な画像を作れるんです。
さらに、高解像度の画像をトレーニングに使ってるから、キャラクターの表情とか背景の細部までめちゃリアルに再現可能。
そして「マルチレベルキャプション」っていう新しい仕組みを採用してて、
タグと自然言語を組み合わせることで、プロンプト(指示)の自由度が大幅アップしてます。
第2章: Illustriousの技術的な話
2.1 データセットと学習の工夫
Illustriousは、Danbooruっていう有名なアニメ画像データセットを使って学習してます。
それだけじゃなくて、合成データも組み合わせて、多様なキャラクターやシーンが生成できるようになってるんですよ。
特にすごいのは「マルチキャプション方式」。画像の内容をタグと自然言語の両方で説明するから、
めちゃくちゃ細かい表現が可能になってます。
2.2 パフォーマンスがスゴイ
Illustriousは、いろんな評価基準でテストされてます。
- ユーザーがどっちの画像を好むかで競わせる「Elo Rating」
- キャラクターの似てる度合いをチェックする「CCIP」
- 安定したランク付けができる「TrueSkill」
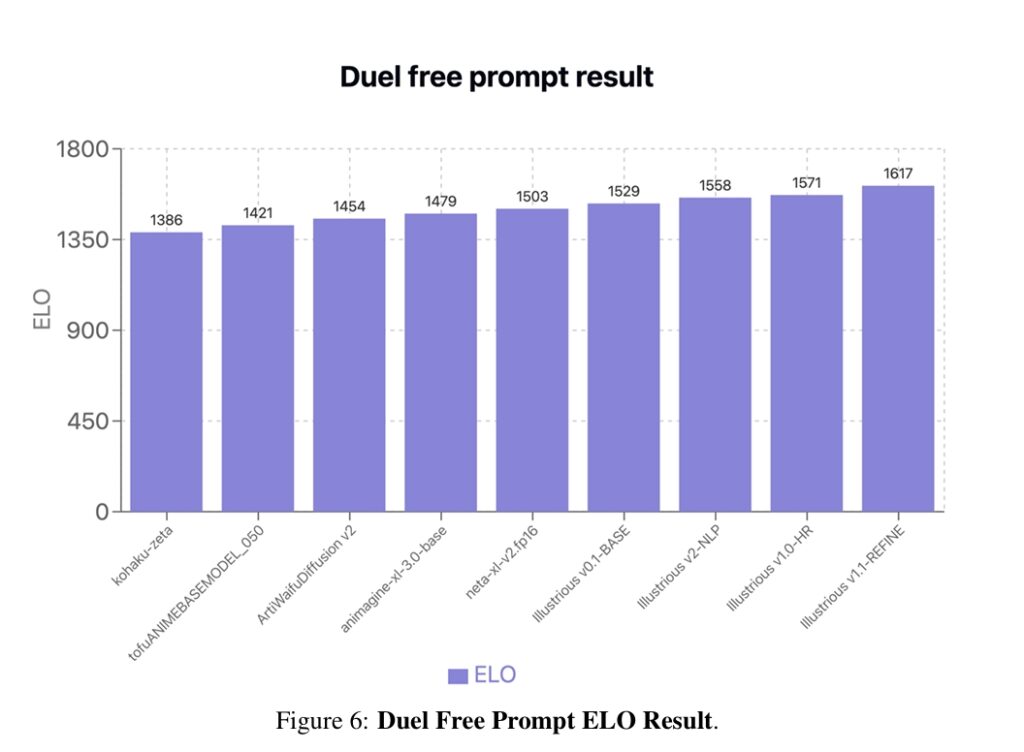
これらのテストで、Illustriousは他の有名モデル(Animagine-XLなど)よりも高評価を獲得してます。
第3章: Illustriousの未来と課題
3.1 こんな課題も
Illustriousはスゴイけど、まだまだ課題もあります。
例えば、CLIPっていうテキストエンコーダーに依存してるから、複雑なキャラクター描写がちょっと苦手。
もっと詳細なキャプションやプロンプトが必要になりそう。
それから、高解像度の画像を生成するには結構な計算リソースが必要。だから、普通のPCじゃ動かないことも。
そのため、現状ではゲーミングPCなどハイスペックのPCが必要になります。
3.2 未来は明るい
それでも、Illustriousには大きな可能性が広がってます。
OCR(光学文字認識)を使って、画像の中に文字をもっと自然に入れるとか、プロンプト制御をもっと進化させるとか、いろんなアイデアが出てきてます。
さらに、オープンソースだから、みんなで改良したり、新しい使い方を試したりできるのも大きなポイントです。
結論
Illustriousはアニメ画像生成の最前線を行くモデルです。
その高い性能と可能性を活かして、これからもたくさんの新しい挑戦が生まれるでしょう。
これをきっかけに、あなたも画像生成の未来に触れてみませんか?

コメント